[TIL] DAY77_CS기초(1/14)
- 11 minsDAY77
2018년 2월 학업계획!
1. 학업계획 방향
- 너무 많은걸 하려는 욕심부리기 보다는 성취 가능하고, 측정 가능한 구체적인 목표 설정
- 부족한 부분을 채우거나 반복해서 익숙해지는 방법도 좋음
- 혼자하기 보다는 여러 명이서 같이하는 게 좋음
- 슬랙 채널을 적극 활용하세요
- 공부하던 흐름을 놓지지 않도록 스위프트 문법을 잊어버리지 말기
- 알고리즘 공부도 해커랭크 같은 곳에서 쉬운것부터 매일 꾸준히 해보는 것도 좋음
- 알고리즘을 풀 때, 자료구조,메모리를 고려해서 의도적으로 여러번 이해하기
2. What To Do & How To Do
(1) CS기초지식 쌓기(10:00~12:30,14:00~17:00/5.5h)
- https://github.com/somedd/Interview_Question_for_Beginner
- 개발상식, 자료구조, 알고리즘, 네트워크, 데이터베이스, 운영체제, 디자인패턴
- Part별 2번 반복
- 처음 공부할 때는 게시된 내용만 이해하고,
- 두번째로 공부할 때는 관련 개념 책 참고해서 공부하기
- 알고리즘은 해커랭크 이용
(2) App따라 만들어보기(18:00~22:00/4h, 토요일, 일요일)
- 내가 좋아하는 App ‘WATCHA’를 따라 만들어보즈아!
(3) 가고싶은 회사 + 내가 개발하고 싶은 서비스 정하기 + 취업준비(포트폴리오)
개발상식(1/6)
OOP(Object Oriented Programming)
- 객체지향프로그래밍의 정의 : 현실 세계를 프로그래밍으로 옮겨와 프로그래밍하는 것.
- 추상화 : 현실 세계의 사물들을 객체라고 보고 그 객체로부터 개발하고자 하는 애플리케이션에 필요한 특징들을 뽑아와 프로그래밍 하는 것
- 장점
- 이미 작성했던 코드에 대한 재사용성이 높다.
- 자주 사용되는 로직을 라이브러리로 만들어두면 계속해서 사용할 수 있으며 그 신뢰성을 확보 할 수 있다.
- 라이브러리를 각종 예외상황에 맞게 잘 만들어두면 개발자가 사소한 실수를 하더라도 그 에러를 컴파일 단계에서 잡아낼 수 있으므로 버그 발생이 줄어든다.
- 내부적으로 어떻게 동작하는지 몰라도 개발자는 라이브러리가 제공하는 기능들을 사용할 수 있기 때문에 생산성이 높아지게 된다.
- 객체 단위로 코드가 나눠져 작성되기 때문에 디버깅이 쉽고 유지보수에 용이하다.
- 데이터 모델링을 할 때 객체와 매핑하는 것이 수월하기 때문에 요구사항을 보다 명확하게 파악하여 프로그래밍 할 수 있다.
- 단점
- 객체 간의 정보 교환이 모두 메시지 교환을 통해 일어나므로 실행 시스템에 많은 overhead가 발생하게 된다. -> 하드웨어의 보완으로 해결됨.
- 객체가 상태를 갖기 떄문에 변수가 존재하고 이 변수를 통해 객체가 예측할 수 없는 상태를 갖게 되어 애플리케이션 내부에서 버그를 발생시킨다는 것이다.
- 이러한 단점은 함수형 프로그래밍 패러다임의 등장 배경을 통해서 알 수 있게됨.
- 객체 지향적 설계 원칙
- SRP(Single Responsibility Principle) : 단일 책임 원칙
- 클래스는 단 하나의 책임을 가져야 하며 클래스를 변경하는 이유는 단 하나의 이유이어야 한다.
- OCP(Open-Closed Principle) : 개방-폐쇄 원칙
- 확장에는 열려 있어야 하고 변경에는 닫혀 있어야 한다.
- LSP(Likov Substitution Principle) : 리스코프 치환 원칙
- 상위 타입의 객체를 하위 타입의 객체로 치환해도 상위 타입을 사용하는 프로그램은 정상적으로 동작해야 한다.
- ISP(Interface Segregation Principle) : 인터페이스 분리 원칙
- 인터페이스는 그 인터페이스를 사용하는 클라이언트를 기준으로 분리해야 한다.
- DIP(Dependency Inversion Principle) : 의존 역전 원칙
- 고수준 모듈은 저수준 모듈의 구현에 의존해서는 안된다.
- SRP(Single Responsibility Principle) : 단일 책임 원칙
- 개념들 정의 : http://asfirstalways.tistory.com/177
자료구조(1/7)
Array vs LinkedList
- Array
- 특징
- 검색 및 값 바꾸기: O(1)
- 논리적 저장 순서와 물리적 저장 순서가 일치한다. 따라서 인덱스(index)로 해당 원소(element)에 접근할 수 있다. -> 찾고자 하는 원소의 인덱스 값을 알고 있으면 Big-O(1)에 해당 원소로 접근 할 수 있다. 즉 random access 가 가능하다 는 장점이 있는 것이다.
- 삭제 or 삭제 : O(n)
- 해당 원소에 접근하여 작업을 완료한 뒤(O(1)), 또 한 가지의 작업을 추가적으로 해줘야 하기 때문에, 시간이 더 걸린다. 만약 배열의 원소 중 어느 원소를 삭제했다고 했을 때, 배열의 연속적인 특징이 깨지게 된다. 즉 빈 공간이 생기는 것이다. 따라서 삭제한 원소보다 큰 인덱스를 갖는 원소들을 shift해줘야 하는 비용(cost)이 발생하고 이 경우의 시간 복잡도는 O(n) 가 된다. 그렇기 때문에 Array 자료구조에서 삭제 기능과 삽입에 대한 시간복잡도의 worst case는 O(n) 이 된다.
- 크기가 고정적
- 검색 및 값 바꾸기: O(1)
- 특징
- LinkedList

- 이 부분에 대한 문제점을 해결하기 위한 자료구조가 linked list이다. 각각의 원소들은 자기 자신 다음에 어떤 원소인지만을 기억하고 있다.
- Tree 구조의 근간이 되는 자료구조이며, Tree에서 사용되었을 때 그 유용성이 드러난다.
- 특징
- 검색 및 값 바꾸기 : O(n)
- 원하는 위치에 삽입을 하고자 하면 원하는 위치를 Search 과정에 있어서 첫번째 원소부터 다 확인해봐야 한다. Array와는 달리 논리적 저장 순서와 물리적 저장 순서가 일치하지 않기 때문이다.
- 삭제 or 삽입 : O(n)
- 각각의 원소들은 자기 자신 다음에 어떤 원소인지만을 기억하고 있기 때문에 삭제와 삽입을 O(1) 만에 해결할 수 있으나, 이것은 일단 삽입하고 정렬하는 것과 마찬가지이다. 이 과정 때문에, 어떠한 원소를 삭제 또는 추가하고자 했을 때, 그 원소를 찾기 위해서 O(n)의 시간이 추가적으로 발생하게 된다.
- 크기가 가변적
- 검색 및 값 바꾸기 : O(n)
- LinkedList 구현
public class Node<T> {
var value : T
var next : Node?
weak var previous : Node?
public init(value : T) {
self.value = value
}
public func add(value : T) {
let newNode = Node.init(value: value)
newNode.next = self.next
self.next = newNode
}
}
let head = Node<String>(value : "1")
head.add(value: "2")
print(head)
네트워크(1/6)
HTTP의 GET과 POST 비교
- 둘 다 HTTP프로토콜을 이용해서 서버에 무엇인가를 요청할 때 사용하는 방식. 하지만, 둘의 특징을 제대로 이해하여 기술의 목적에 맞게 알맞은 용도에 사용해야한다.
- 먼저, 웹이란? : 웹 = WWW = World Wide Web
- 웹의 3요소: HTTP, HTML, URL
- URL(Uniform Resource Locator) : 리소스를 식별하는 주소
- Web Client와 Server
- Web Client : 주로 웹 브라우저로 항상 요청을 하고, URL을 전송한다.
- Server : 클라이언트의 요청에 대해 그에 맞는 적당한 문서(HTML문서)를 전송한다.
- 프록시: 클라이언트와 서버 사이에 존재. 무언가 일을 해 준다.
- 캐싱, 필터링, 로드 밸런싱, 인증, 로깅 등의 다양한 기능을 수행
- 웹의 3요소: HTTP, HTML, URL
- HTTP(HyperText Transfer Protocol)의 정의 : 인터넷에서, 웹 서버와 사용자의 인터넷 브라우저 사이에 문서를 전송하기 위해 사용되는 통신 규약
- WWW 상에서 정보를 주고받을 수 있는 프로토콜. 주로 HTML 문서를 주고받는 데에 쓰인다. TCP와 UDP를 사용하며, 80번 포트를 사용한다. TCP/UDP는 나중에 다시 공부.
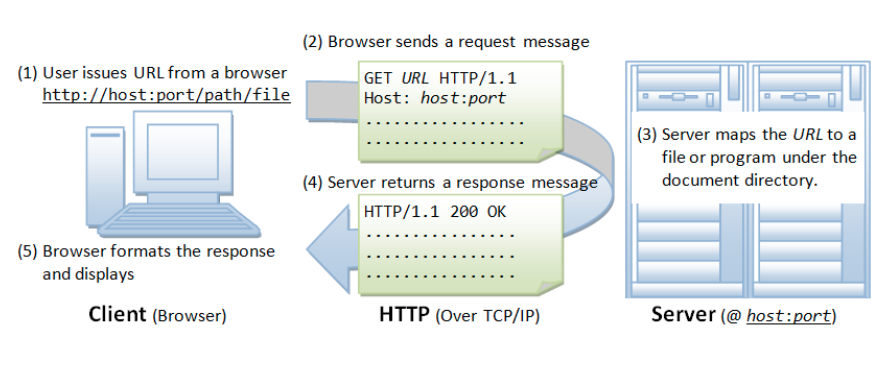
- WWW 상에서 정보를 주고받을 수 있는 프로토콜. 주로 HTML 문서를 주고받는 데에 쓰인다. TCP와 UDP를 사용하며, 80번 포트를 사용한다. TCP/UDP는 나중에 다시 공부.
- GET vs POST
-
HTTP Request 메시지의 구조

-
GET : 요청하는 데이터가 HTTP Request Message의 Header 부분의 url에 담겨서 전송 된다. 때문에 url 상에 데이터가 붙어 request를 보내게 되는 것이다. 이러한 방식은 url이라는 공간에 담겨가기 때문에 전송할 수 있는 데이터의 크기가 제한적이다. 또 보안이 필요한 데이터에 대해서는 데이터가 그대로 url에 노출되므로 GET방식은 적절하지 않다. (ex. password)
-
POST : 요청하는 데이터가 HTTP Message의 Body 부분에 데이터가 담겨서 전송 된다. 때문에 바이너리 데이터를 요청하는 경우 POST 방식으로 보내야 하는 것처럼 데이터 크기가 GET 방식보다 크고 보안면에서 낫다.
-
GET방식과 POST방식의 용도 : 우선 GET은 가져오는 것이다. 서버에서 어떤 데이터를 가져와서 보여준다거나 하는 용도이지 서버의 값이나 상태 등을 변경하지 않는다. SELECT 적인 성향을 갖고 있다고 볼 수 있는 것이다. 반면에 POST는 서버의 값이나 상태를 변경하기 위해서 또는 추가하기 위해서 사용된다.
- 부수적인 차이점을 좀 더 살펴보자면 GET 방식의 요청은 브라우저에서 Caching 할 수 있다. 때문에 POST 방식으로 요청해야 할 것을 보내는 데이터의 크기가 작고 보안적인 문제가 없다는 이유로 GET 방식으로 요청한다면 기존에 caching 되었던 데이터가 요청될 가능성이 존재한다. 때문에 목적에 맞는 기술을 사용해야 하는 것이다.
-
운영체제(1/9)
프로세스와 스레드의 차이
- 프로세스 : 실행 중인 프로그램 으로 디스크로부터 메모리에 적재되어 CPU의 할당을 받을 수 있는 것. 즉, 운영체제로부터 주소 공간, 파일, 메모리 등을 할당받는 프로그램들을 총칭하여 프로세스라고 한다.
- 프로세스는 함수의 매개변수, 복귀 주소와 로컬 변수와 같은 임시 자료를 갖는 프로세스 스택 과 전역 변수들을 수록하는 데이터 섹션 을 포함한다. 또한 프로세스는 프로세스 실행 중에 동적으로 할당되는 메모리인 힙 을 포함한다.
- **MEM구조
- CODE : 실행코드가 들어간다.
- DATA : “Hello”, 전역변수와 같은 값이 들어가 있음.
- HEAP : 객체, 배열이 들어가는 곳. Ex) var a = {1, 2, 3}
- STACK : 함수 안에서 만든 변수가 쌓이는 곳.**
- 프로세스 제어 블록(Process Control Block, PCB)
-
PCB란? 특정 프로세스에 대한 중요한 정보를 저장 하고 있는 운영체제의 자료구조이다. 운영체제는 프로세스를 관리하기 위해 프로세스의 생성과 동시에 고유한 PCB를 생성 한다. 프로세스는 CPU를 할당받아 작업을 처리하다가도 프로세스 전환이 발생하면 진행하던 작업을 저장하고 CPU를 반환해야 하는데, 이때 작업의 진행 상황을 모두 PCB에 저장하게 된다. 그리고 다시 CPU를 할당받게 되면 PCB에 저장되어있던 내용을 불러와 이전에 종료됐던 시점부터 다시 작업을 수행한다.
-
PCB에 저장되는 정보
- 프로세스 식별자(Process ID, PID) : 프로세스 식별번호
- 프로세스 상태 : new, ready, running, waiting, terminated 등의 상태를 저장
- 프로그램 카운터 : 프로세스가 다음에 실행한 명령어의 주소
- CPU 레지스터
- CPU 스케쥴링 정보 : 프로세스의 우선순위, 스케줄 큐에 대한 포인터 등
- 메모리 관리 정보 : 페이지 테이블 또는 세그먼트 테이블 등과 같은 정보를 포함
- 입출력 상태 정보 : 프로세스에 할당된 입출력장치들과 열린 파일 목록
- 어카운팅 정보 : 사용된 CPU시간, 시간제한, 계정번호 등
-
- 스레드(Thread) : 프로세스의 실행 단위
-
한 프로세스 내에서 동작되는 여러 실행 흐름으로 프로세스 내의 주소 공간이나 자원을 공유할 수 있다. 스레드는 스레드 ID, 프로그램 카운터, 레지스터 집합, 그리고 스택으로 구성 된다. 같은 프로세스에 속한 다른 스레드와 코드, 데이터 섹션, 그리고 열린 파일이나 신호와 같은 운영체제 자원들을 공유한다. 하나의 프로세스를 다수의 실행 단위로 구분하여 자원을 공유하고 자원의 생성과 관리의 중복성을 최소화하여 수행 능력을 향상시키는 것을 멀티스레딩 이라고 한다. 이 경우 각각의 스레드는 독립적인 작업을 수행해야 하기 때문에 각자의 스택과 PC 레지스터 값을 갖고 있다.
- 스택을 스레드마다 독립적으로 할당하는 이유 : 즉, 독립적인 실행 흐름을 위해서.
- 스택은 함수 호출 시 전달되는 인자, 되돌아갈 주소값 및 함수 내에서 선언하는 변수 등을 저장하기 위해 사용되는 메모리 공간이므로 스택 메모리 공간이 독립적이라는 것은 독립적인 함수 호출이 가능하다는 것이고 이는 독립적인 실행 흐름이 추가되는 것이다. 따라서 스레드의 정의에 따라 독립적인 실행 흐름을 추가하기 위한 최소 조건으로 독립된 스택을 할당한다.
- PC Resister를 스레드마다 독립적으로 할당하는 이유 : 스레다가 명령어의 어디까지 수행하였는지 기억하기 위해서.
- PC 값은 스레드가 명령어의 어디까지 수행하였는지를 나타나게 된다. 스레드는 CPU를 할당받았다가 스케줄러에 의해 다시 선점당한다. 그렇기 때문에 명령어가 연속적으로 수행되지 못하고 어느 부분까지 수행했는지 기억할 필요가 있다. 따라서 PC 레지스터를 독립적으로 할당한다.
-
데이터베이스(1/6)
데이터베이스
- 데이터베이스(DB)란? 체계화된 데이터의 모임. 즉, 작성된 목록으로써 여러 응용 시스템들의 통합된 정보들을 저장하여 운영할 수 있는 공용 데이터들의 묶음
- 데이터베이스를 사용하는 이유
- 데이터베이스가 존재하기 이전에는 파일 시스템을 이용하여 데이터를 관리하였다. (현재도 부분적으로 사용되고 있다.) 데이터를 각각의 파일 단위로 저장하며 이러한 일들을 처리하기 위한 독립적인 애플리케이션과 상호 연동이 되어야 한다. 이 때의 문제점은 데이터 종속성 문제와 중복성, 데이터 무결성이다. 이를 해결하기 위해서 사용한다.
- 데이터베이스의 특징
- 데이터의 독립성
- 물리적 독립성 : 데이터베이스 사이즈를 늘리거나 성능 향상을 위해 데이터 파일을 늘리거나 새롭게 추가하더라도 관련된 응용 프로그램을 수정할 필요가 없다.
- 논리적 독립성 : 데이터베이스는 논리적인 구조로 다양항 응용 프로그램의 논리적 요구를 만족시켜줄 수 있다.
- 데이터의 무결성
- 여러 경로를 통해 잘못된 데이터가 발생하는 경우의 수를 방지하는 기능으로 데이터의 유효성 검사를 통해 데이터의 무결성을 구현하게 된다.
- 데이터의 보안성
- 인가된 사용자들만 데이터베이스나 데이터베이스 내의 자원에 접근할 수 있도록 계정 관리 또는 접근 권한을 설정함으로써 모든 데이터에 보안을 구현할 수 있다.
- 데이터의 일관성
- 연관된 정보를 논리적은 구조로 관리함으로써 어떤 하나의 데이터만 변경했을 경우 발생할 수 있는 데이터의 불일치성을 배제할 수 있다. 또한 작업 중 일부 데이터만 변경되어 나머지 데이터와 일치하지 않는 경우의 수를 배제할 수 있다.
- 데이터 중복 최소화
- 데이터베이스는 데이터를 통합해서 관리함으로써 파일 시스템의 단점 중 하나인 자료의 중복과 데이터의 중복성 문제를 해결할 수 있다.
- 데이터의 독립성
- 데이터베이스 성능
- 데이터베이스의 성능 이슈는 디스크 I/O를 어떻게 줄이느냐에서 시작된다. 디스크 I/O란 디스크 드라이브의 플래터(원판)을 돌려서 읽어야 할 데이터가 저장된 위치로 디스크 헤더를 이동시킨 다음 데이터를 읽는 것을 의미한다. 이 때 데이터를 읽는데 걸리는 시간은 디스크 헤더를 움직여서 읽고 쓸 위치로 옮기는 단계에서 결정된다. 즉 디스크의 성능은 디스크 헤더의 위치 이동 없이 얼마나 많은 데이터를 한 번에 기록하느냐에 따라 결정된다고 볼 수 있다.
- 그렇기 때문에 순차 I/O가 랜덤 I/O보다 빠를 수 밖에 없다. 하지만 현실에서는 대부분의 I/O 작업이 랜덤 I/O 이다. 랜덤 I/O를 순차 I/O로 바꿔서 실행할 수는 없을까? 이러한 생각에서부터 시작되는 데이터베이스 쿼리 튜닝은 랜덤 I/O자체를 줄여주는 것이 목적이라고 할 수 있다.